





Primer
Helping large organizations transform information overload into decision advantage
DCVC, which co-led Primer’s Seed and led its Series A, has re-committed significantly to Primer AI’s $40M+ Series B. This funding will help Primer further commercialize their software, which can read, understand, and summarize vast amounts of unstructured text and data. Primer’s software automates human analysts’ most tedious tasks: digging through hundreds of documents and writing summaries of what they’ve read. The analysts get to spend their time on more complex, engaging problems instead. We invested in Primer because they are run by world-class experts, replace resource-intensive manual tasks with intelligent software, and will disrupt the fundamental research process most industries rely on, across every language, around the globe. We’re proud to support Primer as they look for underlying truth in a complex world.
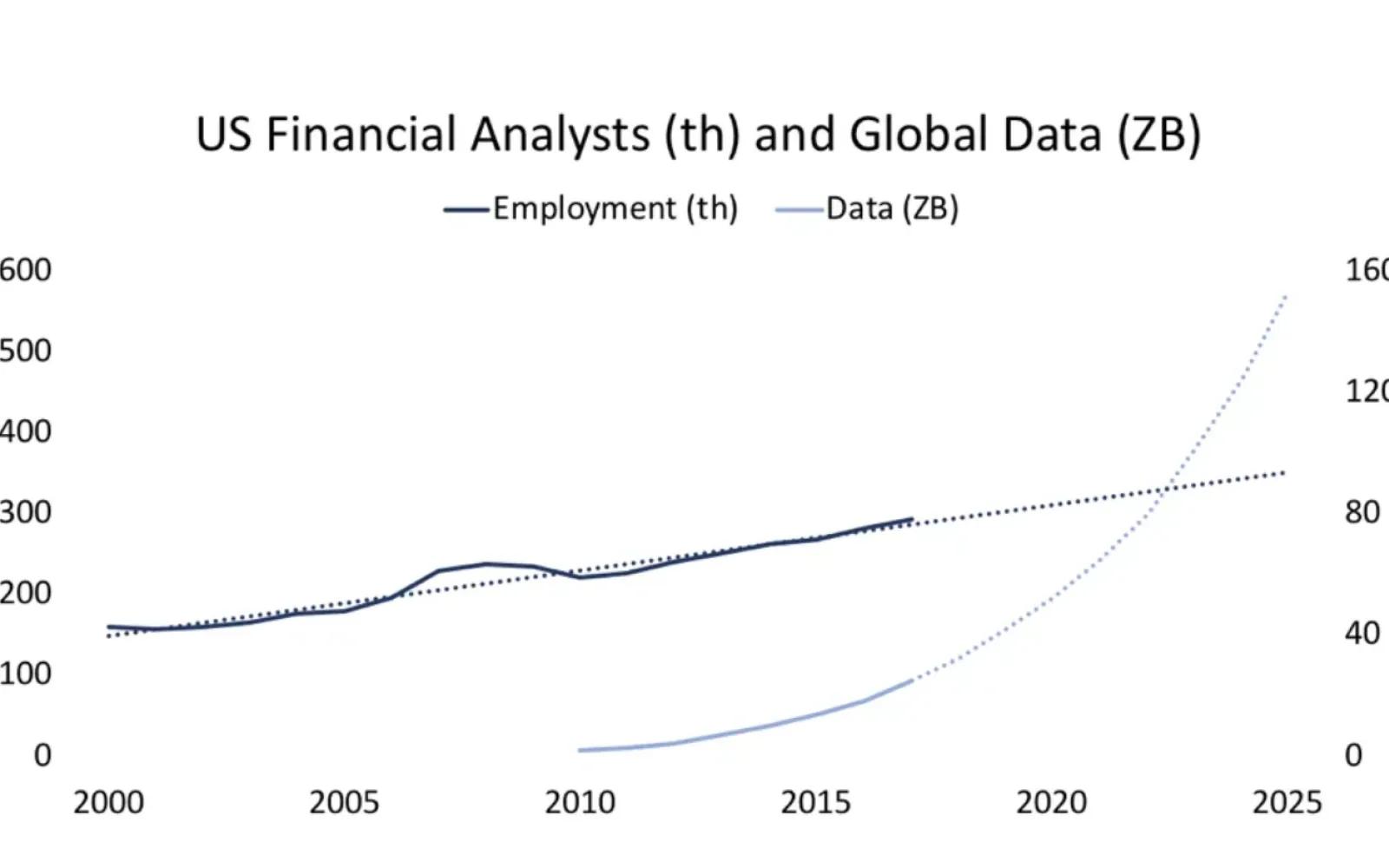
A Tale of Two Curves: Data & Analysts
Humans are formidable information-processing machines. We can identify images in milliseconds, read hundreds of words per minute, and quickly generate commentary on the information we consume. However, as the amount of information we absorb climbs, our ability to process it diminishes. Author Daniel J. Levitin put the situation well:
In 2011, Americans took in five times as much information every day as they did in 1986 — the equivalent of 174 newspapers. During our leisure time, not counting work, each of us processes 34 gigabytes, or 100,000 words, every day. The world’s 21,274 produce 85,000 hours of original programming every day as we watch an average of 5 hours of television daily, the equivalent of 20 gigabytes of audio-video images. That’s not counting Youtube, which uploads 6,000 hours of video every hour.
(This article is from 2015. By 2017, the Youtube figure jumped to 400 hours per minute, or 24,000 hours per hour.)
We’re all pummeled by fire hose streams of information, but we can throttle them when we need to: disabling our notifications; logging off social media; desperately locking our phones in boxes when all else fails.
Analysts, however, are tasked with turning information fire hoses into comprehensible reports. The decisions they inform are critical and time-sensitive. An analyst’s report could determine a multibillion-dollar company’s business plan, quantify uncertain investment risks, or explain sensitive situations where lives hang in the balance. As the data we generate outpaces the people processing it, analysts face a dangerous intelligence gap.
The National Geospatial Agency said ‘If we were to actually have analysts looking at every bit of data that \[…] we’ve collected, we’d need 8 million analysts.’
CEO Sean Gourley
This intelligence gap exists because “we’re biologically constrained by a limit to the volume, speed, and complexity of the information that we understand,” says Primer CEO Sean Gourley. Gourley turned to computers instead. Computers could fix the intelligence gap at a speed and scale humans couldn’t. Machines have “a different kind of intelligence,” he says, and they have different limits than humans do. Machines have problems with precision and humans have problems with recall.
Say you were asked you to list every event in the women’s rights movement this year. Precision measures your answer’s accuracy: how many of your events were women’s rights events? (A/(A+C)) Recall measures your answer’s completeness: of every women’s rights event last year, what portion did you cover? (A/(A+B))
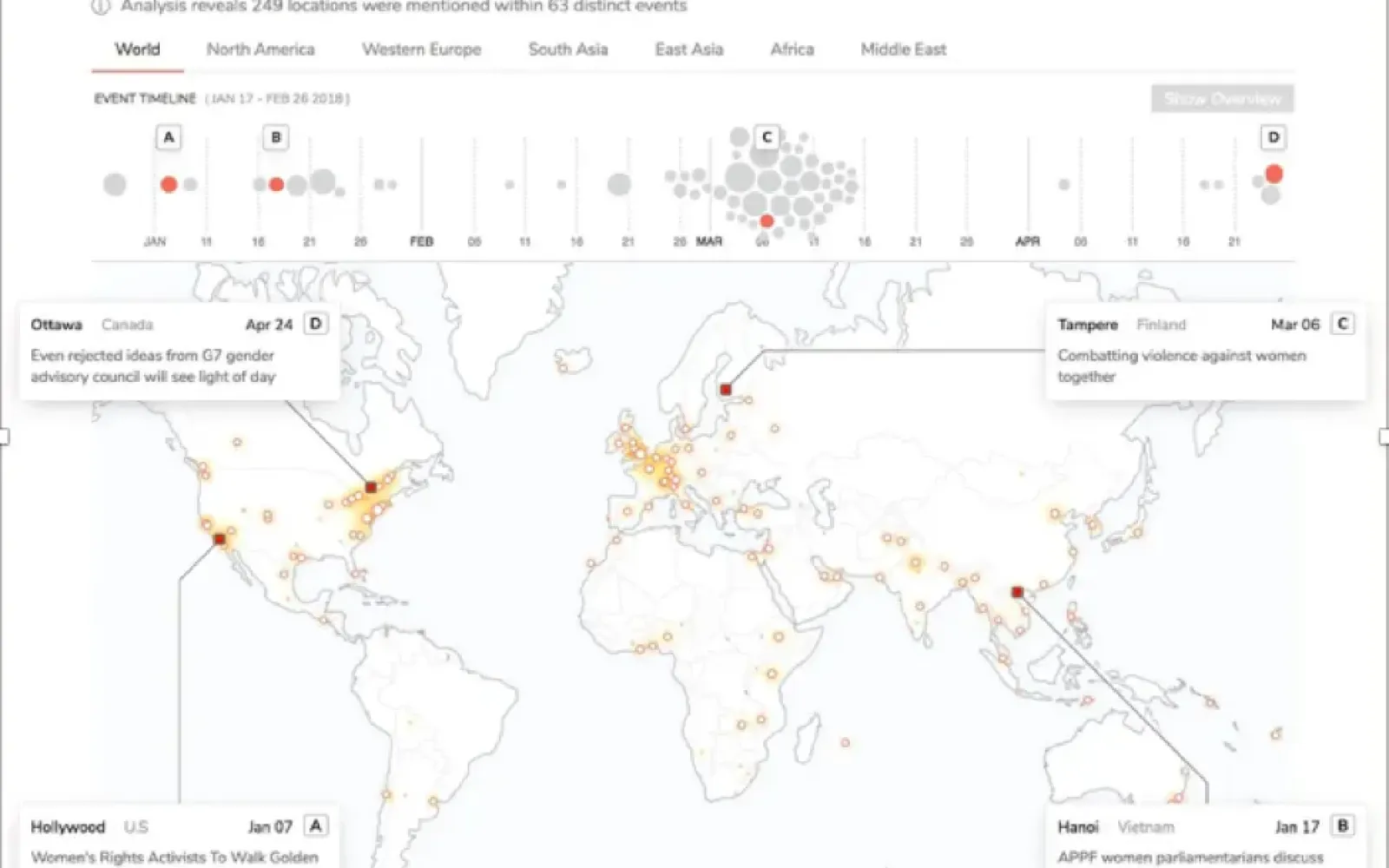
Humans are very precise. You wouldn’t lump “Hurricane Florence” in with women’s rights events — but an algorithm might. On the other hand, you might not have heard about the Asia-Pacific Parliamentary Forum discussing gender equality in Hanoi. It probably wasn’t in your news feed. If it was, you might not have read it (and if you did, you’ve probably forgotten about it by now). The algorithm won’t forget.
Primer makes the most of digital recall and human precision. Here’s the company’s computer-generated report on women’s rights events in early 2018, complete with a map and timeline. It would have taken me days to curate a report this detailed, and I would have missed many of the events. Primer can assemble a comprehensive report in minutes instead. Their algorithms have 20 – 30% better recall than humans do. They score a few points lower in precision, but analysts’ feedback improves their performance over time. Packing days of an analyst’s work into a program that takes moments to run (and writes a better report) will vastly improve their workday.
Manifold Engines
Primer’s software distills millions of unstructured data sources into concise summaries by a) breaking documents down into the concepts they discuss, b) identifying the relationships among those concepts, and c) reporting patterns in the relationships humans might miss. They do this with 6 algorithmic “engines”:
Structure turns documents into a set of concepts, and Ensemble de-duplicates and assembles those concepts into models informed by multiple documents. Event uses timestamps and language processing to group articles into the events they discuss. Context finds other information relevant to events and constructs a probable causal timeline. Difference discovers mismatches between data sources. For instance, two contract drafts may have small (but important) word changes, or Chinese and English news datasets may cover the same event in different ways. Finally, Story turns the data and its analysis into a concise, readable summary. (You can read more detailed engine descriptions in our Deep Dive, here.)
Getting to Ground Truth
Primer’s software is impressive, but they won’t use it to fully automate analysts’ jobs anytime soon. Rather, Primer wants to “write that first draft”, which analysts can edit themselves. Think of it as an immensely helpful assistant, not a job-threatening automaton. After all, the decisions analysts inform are ultimately human ones, embedded in complex contexts difficult to describe to computers. These algorithms just speed up work that’s already underway.
ArXiv is a good illustration of the deluge of information we face. You can see the timeline of scientific progress in arXiv. But it is not human readable. You can’t make sense of all of it, even with a PhD.
John Bohannon
Primer is actually using its software to accelerate its own development. John Bohannon, Primer’s Director of Science, built a tool called Primer Science to process all the new artificial intelligence research published to arXiv. It’s easy to understand why: researchers posted 97 new AI papers to the repository last week. The papers sport titles like “Analytical Formulations for the Level Based Weighted Average Value of Discrete Trapezoidal Fuzzy Numbers”. If each graduate-level article takes about an hour to read and fully understand, you would have to work 14 hours a day every week to keep pace with new papers. Primer uses their own software to summarize these papers and flag the most important ones. They apply what they learn to improve their software.
Primer wants to help analysts find ground truth. However, malicious actors could use text generation to write misinformation instead, flooding the internet with individualized, A/B‑tested computational propaganda. “The future of political manipulation will be automated,” warns Gourley. Tools like Primer may become critical for discovering truth in a distorted information ecosystem. We may all have to become analysts to make informed decisions.
Analysts are part of every industry data touches. They help run governments and financial institutions, but they also keep your utilities running, improve factory operations, and keep public transit operating smoothly. Many people also conduct complex analyses without the analyst title: professionals in medicine, research, and law have to process huge amounts of information to do their jobs. Intelligence analysis is only the beginning for Primer. The company already serves a material — but undisclosable — number of the 17 US intelligence agencies (through intermediary In-Q-Tel), and they also streamline research for Walmart and GIC, Singapore’s sovereign wealth fund.
We invested in Primer because their technology will enable multiple huge industries save untold amounts of time and money. The company is years ahead of the competition in automatic text summarization, and their customer list already proves the value they bring to analysts. Primer runs on the kind of feedback loop that we look for in our portfolio companies, using the software they build to improve themselves. We’re proud to support Primer as they fundamentally improve the lives – and decision quality – of researchers and analysts across huge global industries, enabling more human (and humane) decisions to be made at machine speed.



